Probabilistic Availment
Posted on December 18, 2019
Introduction
This post will tackle two probability questions inspired by a recent Civil Procedure practice test I took. Consider a company that randomly buys $300$ loans from houses all over the United States. What is the probability that at least one of the loans is for a house in Florida? What is the probability that there is a loan for at least one house in each of the fifty states?
The legal purpose for this analysis is determining purposeful availment, a murky part of personal jurisdiction summarized (over)simply enough as "if you meant to business in a certain state, you can be sued there." If a business only had $50$ loans, then they could make a much better case that they don't intend to be subject to a particular state. But for a large number like $300$, intuition tells you that the likelihood is much higher.

Is Florida Targeted?
For the sake of simplicity, assume each state is targeted with equal probability. You could recast the problem as $300$ state quarters if it helps get over the hump of population difference between states like Wyoming and California.
If there was just one state, the probability that it isn't Florida is $\frac{49}{50}=.98$. Similarly, if $300$ states are selected, the probability none are Florida is just $.98^{300}$. So the probability that at least one is Florida is the complement:
$$ 1-.98^{300} = 99.8\%.$$With this many loans there is high certainty that Florida is at least one of them. Side note: $99\%$ may not be high enough, read the top of page 20 of Justice Kagan's dissent in the recent SCOTUS gerrymandering case. Apparently $99\%$ wasn't good enough for the majority.
So how many are loans are sufficient for $50\%$, $95\%$, or $99.7\%$ certainty? This is a simple exercise in logarithms. Let there be $n$ loans and a certainty $p$. Then
\begin{eqnarray*} 1-.98^n &=& p \\ .98^n &=& 1-p \\ \log(.98^n) &=& \log(1-p) \\ n\log(.98) &=& \log(1-p) \\ n &=& \frac{\log(1-p)}{\log(.98)} \\ \end{eqnarray*} So for $p=50\%$ you need $n=35$ houses, $p=95\%$ you need $n=149$ houses, and for $p=99.7\%$ you need $n=288$ houses.Is Every State Targeted?
This is a considerably harder problem. We must consider significantly more cases than just Florida's absence. First, we can tackle it with a simulation for some perspective. The following code does the trick.
import random
num_simulations = 10000
num_states = 50
num_loans = 300
count = 0
for _ in xrange(num_simulations):
coll = set([])
for _ in xrange(num_loans):
coll.add(random.randrange(num_states))
if len(coll) == 50:
count += 1
print count/float(num_simulations)
This is helpful, but not satisfying. Can we solve this analytically?
My first intuition was an extension of the previous section, just take the probability of one state and multiply it out 50 times, $\left(1-.98^{300}\right)^{50}$. Unfortunately, there is an oversight here. The discrepancy is hard to spot with $50$ states, but becomes more and more apparent as the problem is recasted with fewer states.
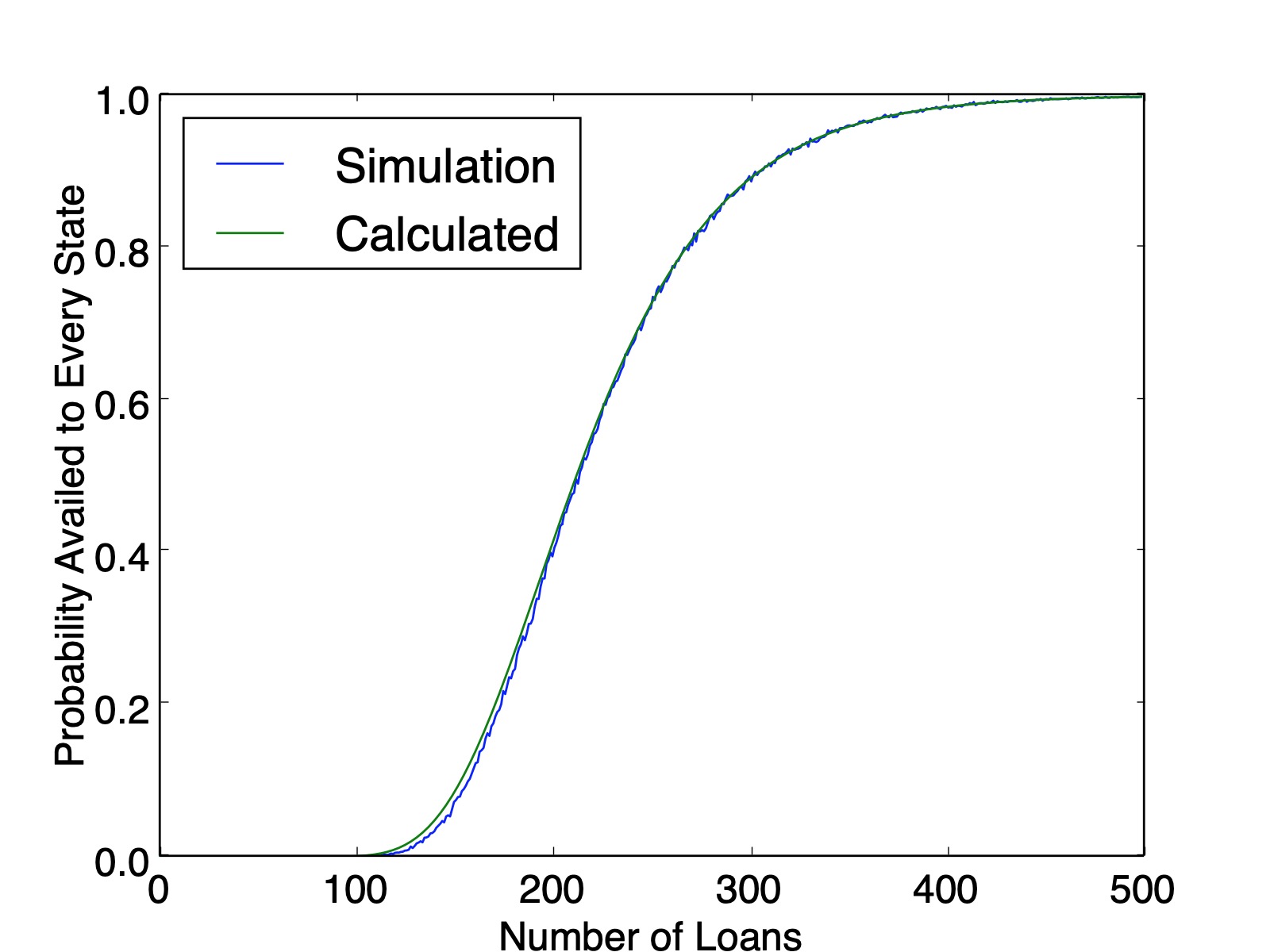
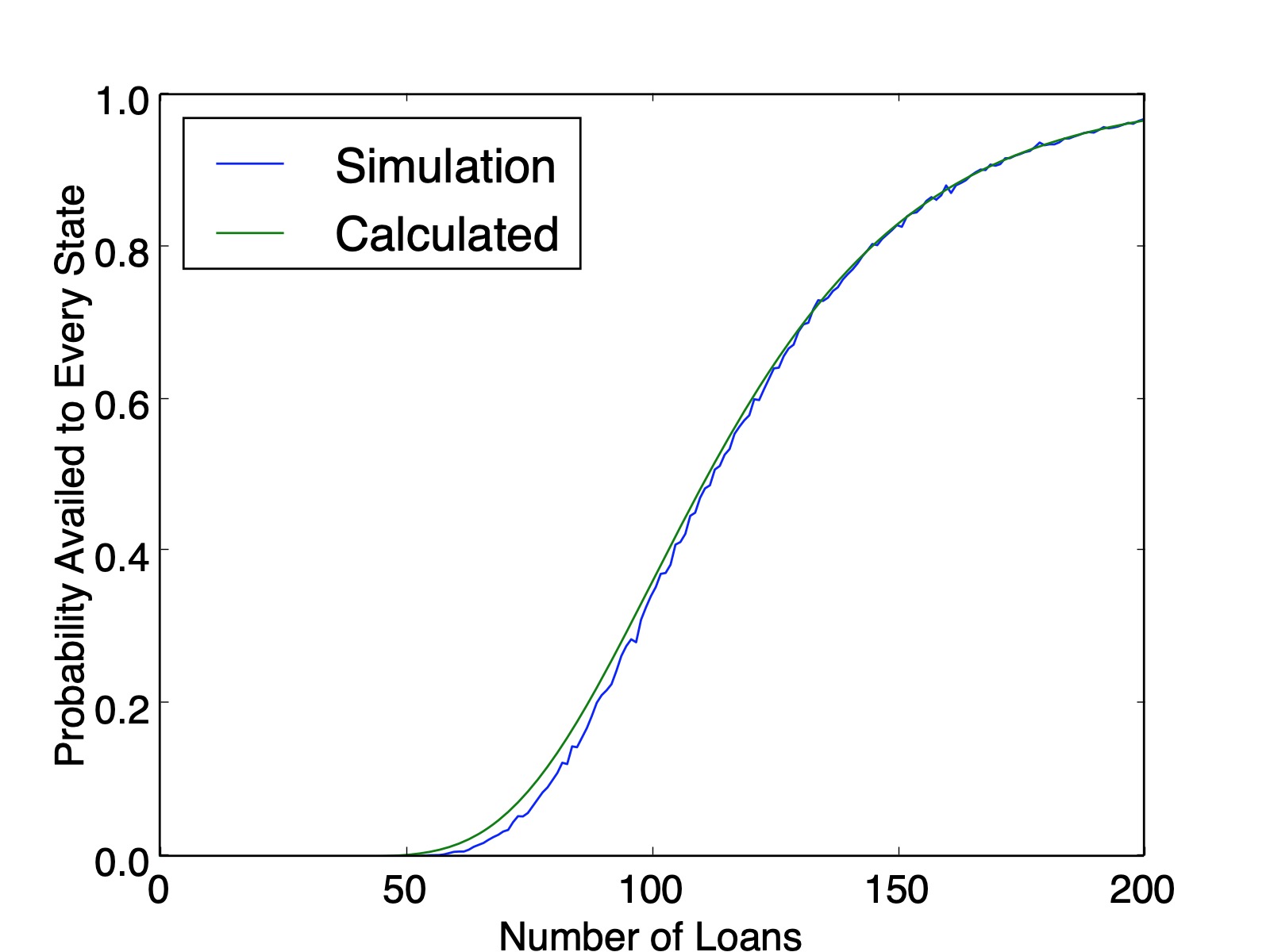
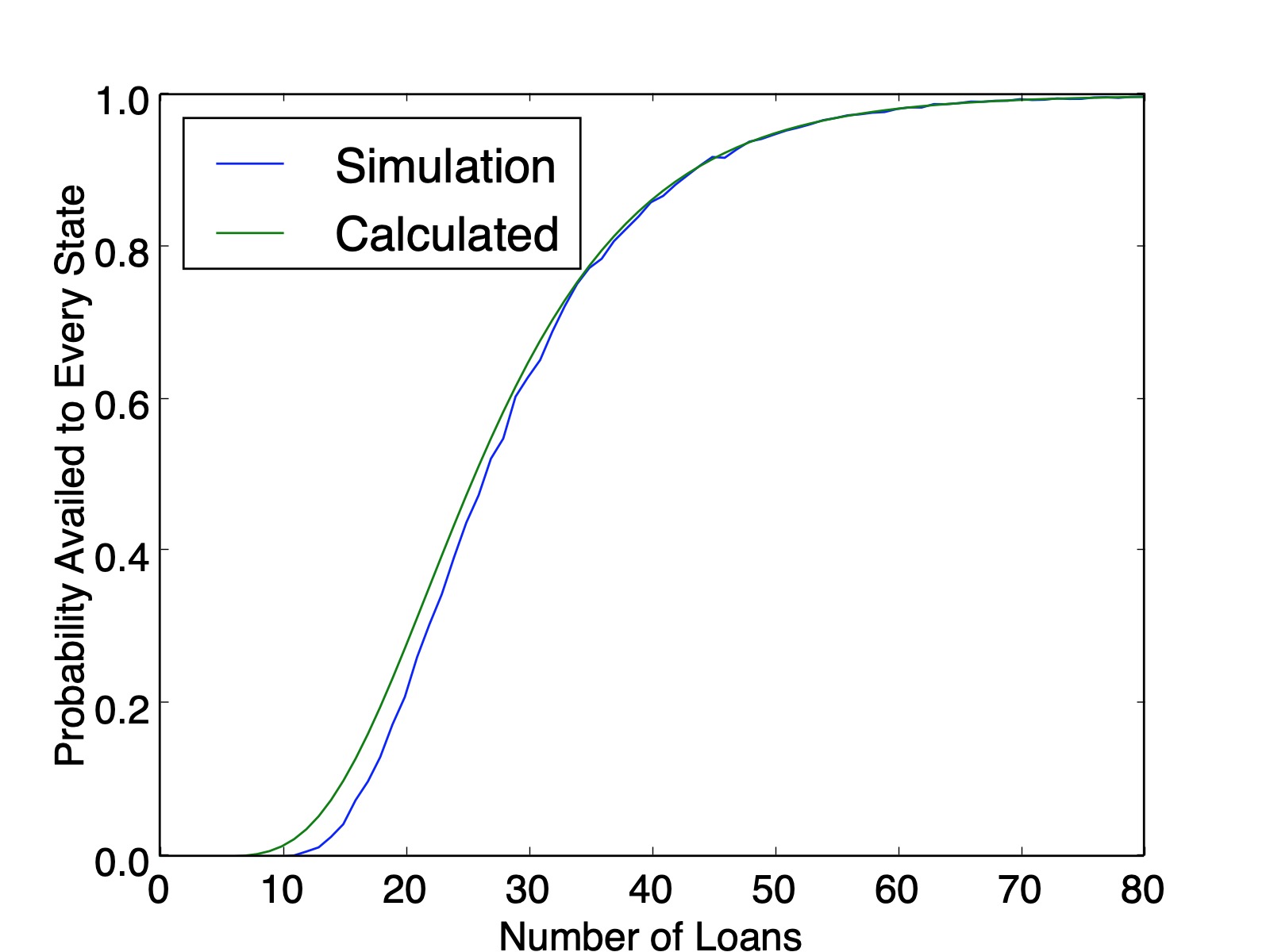
The issue here is that after you determine that Florida is present in the list and you try to move on to next state, that subsequent probability is constrained by how many times Florida came up in the first pass through the list. This dependence cascades down with combinatorial complexity.
Counting a Simpler Case
For illustrative purposes, let's walk through a simpler case, $3$ states and $5$ loans. This will "prove" the accuracy of the simulation and lay out the means for (and complexity of) an algorithm to tackle larger numbers.
There are $3^5=243$ possible ways for the loans to be divided up. We will brute force count all $243$ outcomes by arranging into three buckets: one state, two state, and three state. Call the states $A$, $B$, and $C$ and treat the loan distribution like 5-letter words comprised of these letters.
The one-state cases are (quite trivially) $AAAAA$, $BBBBB$, and $CCCCC$.
It gets trickier with more states. For a two-state solution, consider the alphabetical pairs $(A,B)$, $(A,C)$, and $(B,C)$. These pairs can fit into the words summarized in the table below. (The first letter in the ordered pair matches with $X$ and the second with $Y$.)
| Pattern | Number of Combinations |
|---|---|
| $XXXXY$ | $\binom{5}{1}=5$ |
| $XXXYY$ | $\binom{5}{2}=10$ |
| $XXYYY$ | $\binom{5}{3}=10$ |
| $XYYYY$ | $\binom{5}{4}=5$ |
Using the $3$ pairs and $5+10+10+5=30$ arrangements, there are $3\cdot 30=90$ two-state solutions. Ordering the three pairings above ensures we don't overcount. For a three-state solution, there is only one alphabetical order $(A,B,C)$. These pairs can fit into the words summarized in the table below.
| Pattern | Number of Combinations |
|---|---|
| $AAABC$ | $\frac{5!}{3!}=20$ |
| $AABBC$ | $\frac{5!}{2!2!}=30$ |
| $AABCC$ | $\frac{5!}{2!2!}=30$ |
| $ABCCC$ | $\frac{5!}{3!}=20$ |
| $ABBCC$ | $\frac{5!}{2!2!}=30$ |
| $ABBBC$ | $\frac{5!}{3!}=20$ |
So there are $150$ three-state solutions. Therefore, the probability that every state is availed is $\frac{150}{243}=0.6173$, which matches the simulation value plotted below ($0.6161$ calculated from $100,000$ simulations). And as a sanity check, our counting method produced $150+90+3=243$ lists.
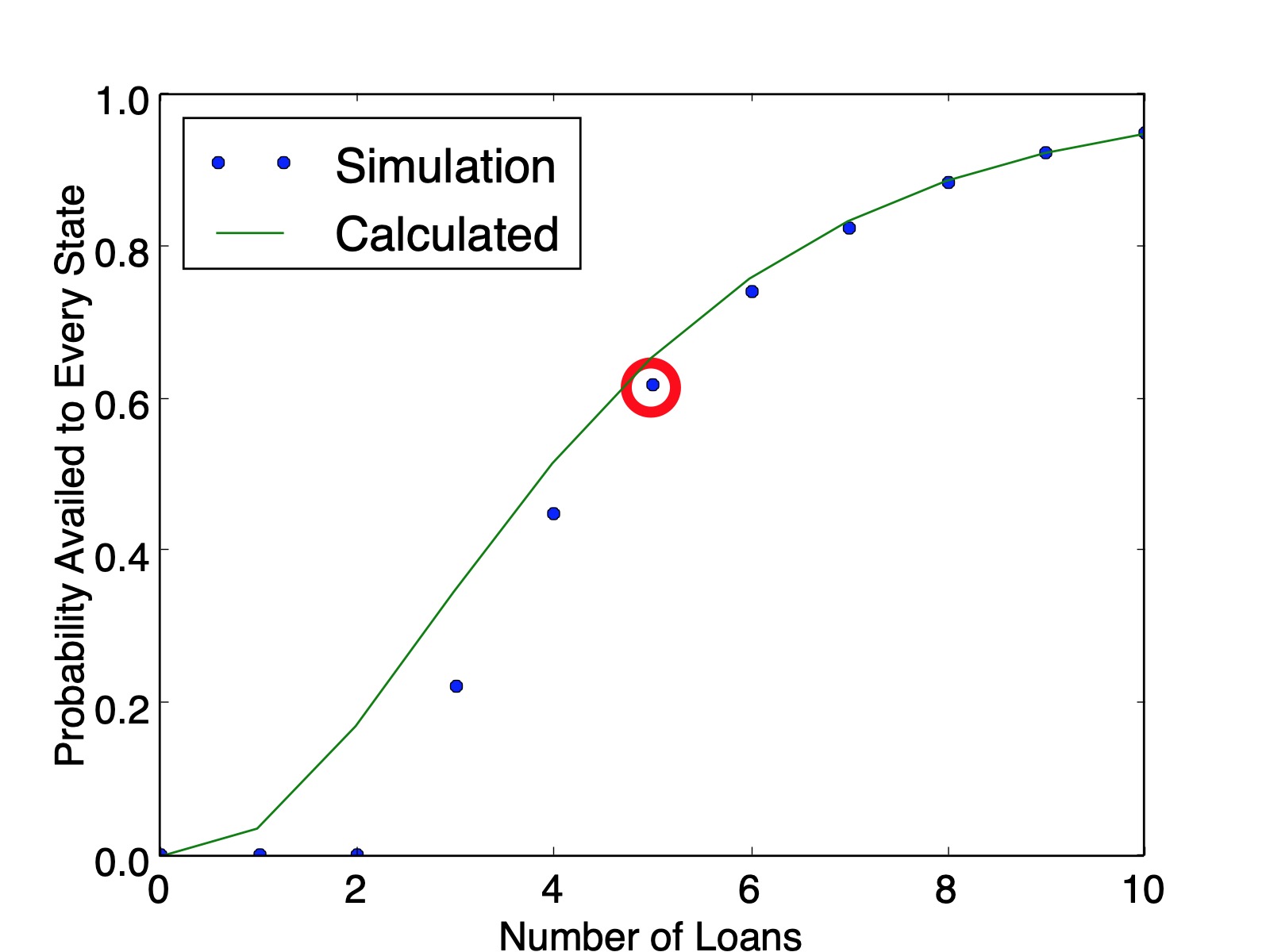
Another Way to Count The Same Thing
Consider the following alternate approach for counting the $5$-loan, $3$-state problem. We will generate the number of lists where the states $A$, $B$, and $C$ show up $2$, $2$, and $1$ times respectively. First, state $A$ can show up in $\binom{5}{2}=10$ of the five locations. Remove the $2$ instances of state A from the list; now state $B$ can show up in $\binom{3}{2}=3$ remaining ways. Once $B$'s locations are picked, there is only one spot remaining for state $C$. Therefore the total number of ways to order this set is $\binom{5}{2}\cdot \binom{3}{2}\cdot \binom{1}{1} = 30$.
The same procedure is computed for all $\binom{4}{2}=6$ partitions of the $5$ states into $3$ non-empty groups in the table below.
| Pattern | Number of Combinations |
|---|---|
| $(1,1,3)$ | $\binom{5}{1}\cdot \binom{4}{1}\cdot \binom{3}{3}=20$ |
| $(1,2,2)$ | $\binom{5}{1}\cdot \binom{4}{2}\cdot \binom{2}{2}=30$ |
| $(1,3,1)$ | $\binom{5}{1}\cdot \binom{4}{1}\cdot \binom{1}{1}=20$ |
| $(2,1,2)$ | $\binom{5}{2}\cdot \binom{3}{1}\cdot \binom{2}{2}=30$ |
| $(2,2,1)$ | $\binom{5}{2}\cdot \binom{3}{2}\cdot \binom{1}{1}=30$ |
| $(3,1,1)$ | $\binom{5}{3}\cdot \binom{2}{1}\cdot \binom{1}{1}=20$ |
This approach affords us a new insight: a clear look at the combinatorial complexity required to count this. We must count the ways to arrange letters for every partition of loans among states. For $5$ loans and $3$ states there are $\binom{4}{2}=6$ partitions, but for $300$ loans and $50$ states there are $\binom{299}{49}=5.19\times 10^{56}$ partitions.
It also affords a nice way to visualize different computations. The $5$-loan, $3$-state problem is a bit bland, but here is a flow chart of the paths to calculate all arrangements for the $6$-loan, $4$-state problem.
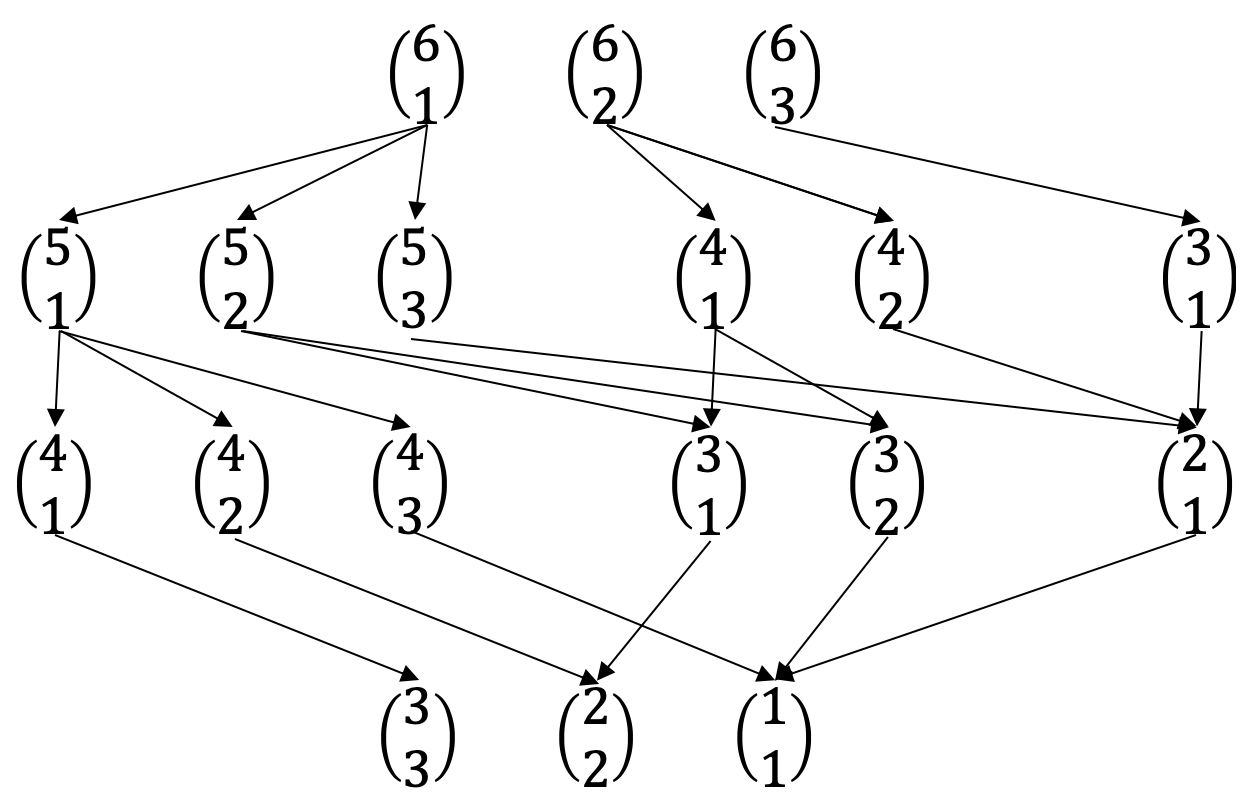
The recursive nature of these patterns lends itself to either recursive solutions, or potentially even a dynamic programming algorithm. That said, the simulations were a lot easier to generate and the combinatorial complexity of the problem makes it intractable for large numbers.
Manipulating Res Ipsa
Posted on October 13, 2019
Introduction and Example
A recent torts cases from class (Byrne v. Boadle) served as the introduction to a class of problems where negligence could be considered probabilistically. This set of problems mirrors the more well-known "false positive" problem. Here are two ways to state what is mathematically the same exercise.
"False Positive" problem: A disease afflicts $0.1\%$ of a population. A test exists for the disease, and will show positive $90 \% $ of the time if you have the disease and $1\%$ of the time if you don't (false positive). If you test positive, what is the probability you have the disease?
Negligence problem: Employees of a company act negligently $0.1\%$ of the time they load barrels next to a window. If they act negligently, an accident occurs $90\%$ of the time. When they are not negligent, an accident occurs $1\%$ of the time. If an accident occurs, what is the probability it was due to negligence?
Both have the same solution (we'll use the negligence nomenclature). Define $P_1$, $P_2$, and $P_3$ per the table below.
| Probability | Disease Problem | Negligence Problem |
|---|---|---|
| $P_1=1\%$ | False positive | Accident, not acting negligently |
| $P_2=90\%$ | True positive | Accident, acting negligently |
| $P_3=0.1\%$ | Prevalence of disease | Rate of negligence |
Let's say an accident occurred. The probability an accident occurs through negligence is $P_{negligence}=P_2\cdot P_3=0.00999$. The probability an accident occurs without negligence is $P_{no-negligence}=P_1\cdot(1-P_3) = 0.0009$. Therefore the probability it was due to negligence is: $$ \frac{P_{negligence}}{P_{negligence}+P_{no-negligence}} = 8.3\%.$$ So $8.3\%$ of the time it is due to negligence (or isomorphically, there is an $8.3 \% $ chance you have the disease despite a positive test).
So should this example drive our intuition? Unless this pattern of low rates of negligence holds for a majority of inputs, the answer is a resounding no.
Let's change the problem slightly by making the probability of accident from non-negligence $P_1=0.1\%$ and the rate of negligence $P_3=1\%$. Intuition would tell you negligence is more likely to have been the cause, but by how much? If you work through the same math, the probability the accident was due to negligence now becomes $90.1\%$. Clearly, this problem is susceptible to manipulation through small changes in the inputs.
DIY Inputs
Try a few different cases yourself and see if you can game the outcome. What are the driving variables?Changing $P_1$ and $P_3$
We were able to "flip" the outcome by flipping $P_1$ and $P_3$, so let's look at the probability of negligence as we vary those two variables. Plots can be generated with the following code.
import matplotlib.pyplot as plt
steps = 201
array2d = [range(steps) for _ in range(steps)]
interval = .0005
for i in range(steps):
for j in range(steps):
p1 = interval*(i+1) # probability of drop if properly handled
p2 = .20 # probability of drop if improperly handled
p3 = 1-interval*(j+1) # probability of handled properly
pa = p1*p3 # handled properly but dropped
pb = (1-p3)*p2 # handled improperly and dropped
p_proper = pa/(pa+pb)
array2d[j][i] = p_proper
plt.contourf(array2d, 9, vmin=0.0, vmax=1.0, origin='lower',
extent=[interval * 100, interval * steps * 100, interval * 100, interval * steps * 100],
cmap='seismic')
cbar=plt.colorbar()
plt.xlabel('$P_1$, probability of accident, not acting negligently (%)')
plt.ylabel('$P_3$, rate of negligence (%)')
plt.title('Probability that Accident Happened through Negligence, $P_2 = 20\%$')
cbar.set_ticks([0, .2, .4, .6, .8, 1])
cbar.set_ticklabels([0, .2, .4, .6, .8, 1])
plt.show()
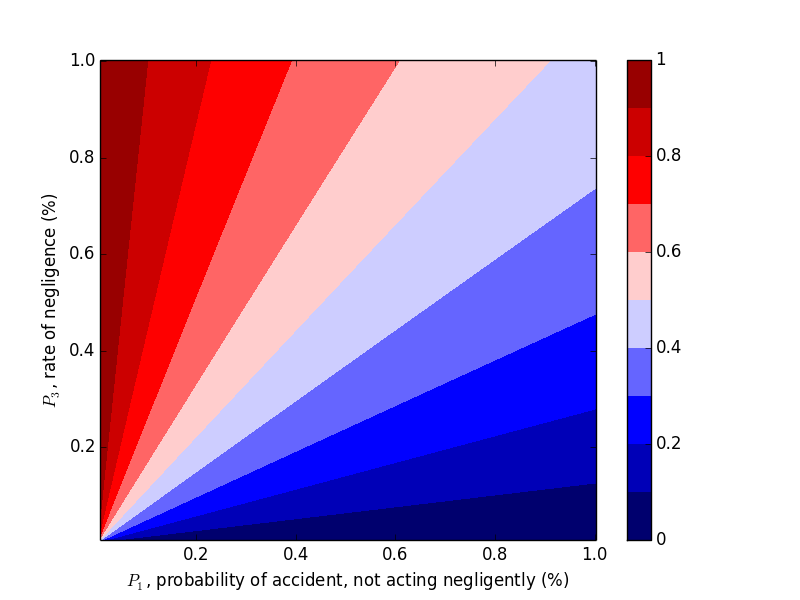
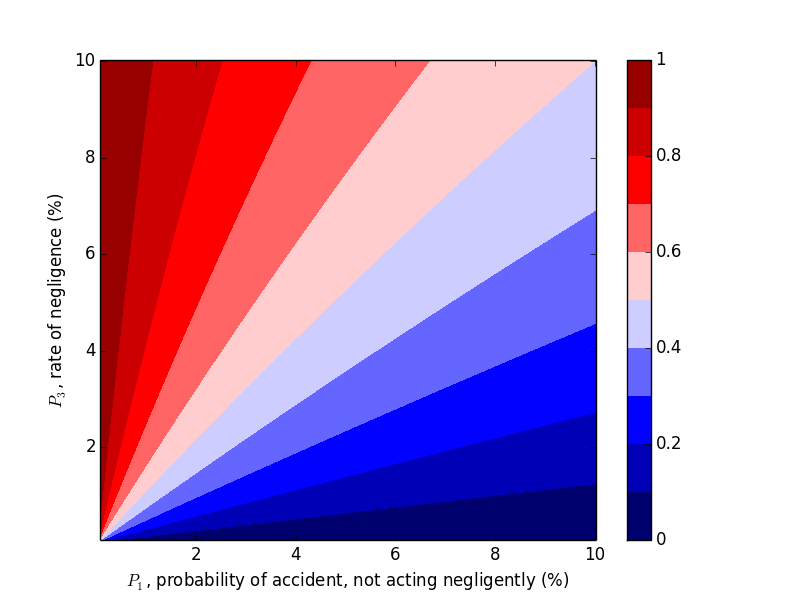
This trend makes sense in hindsight, but one should hardly be expected to carry this intuition around with them, naturally or otherwise.
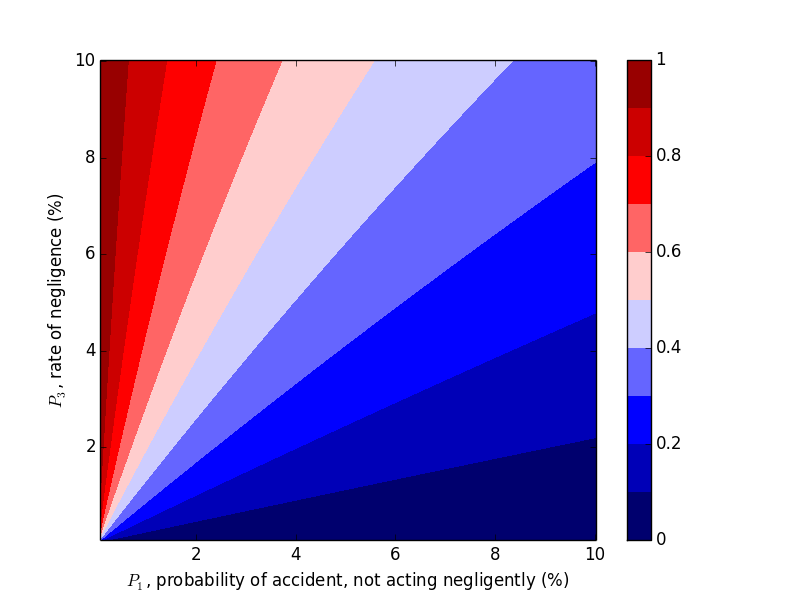
Changing $P_2$
Now let's work with $P_2$. Compare the above plots where $P_2=0.9$ to the plots below where $P_2=0.2, 0.5$. We would expect decreasing $P_2$, probability of an accident given negligence, to decrease the probability of negligence given an accident, which the plots below confirm.
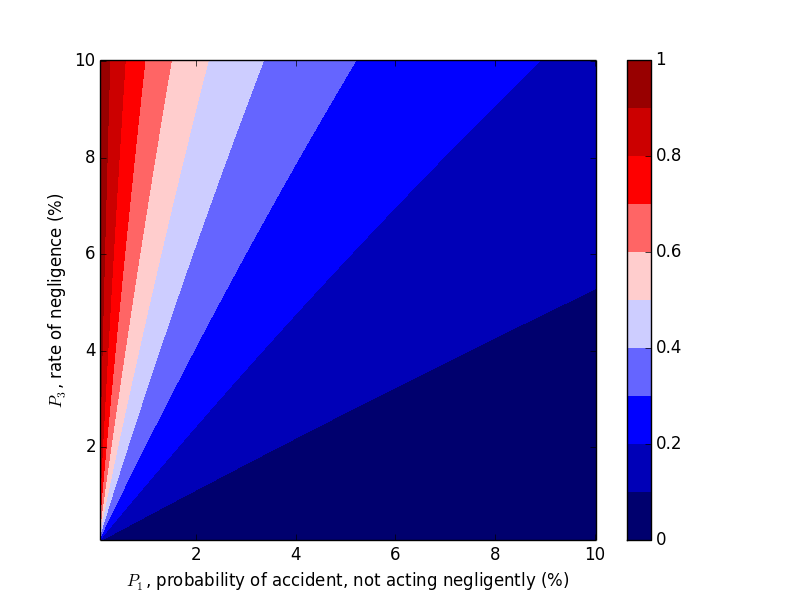
Takeaways
With these results, we can develop a general intuition:
- If $P_2$ is sufficiently low, an accident is probably not due to negligence.
- If $P_2$ is sufficiently high and $P_1>P_3$, then the accident was probably not due to negligence.
- If $P_2$ is sufficiently high and $P_1 < P_3$, then the accident was probably due to negligence.
That said, a more important takeaway here is simpler: don't let a limited data set drive your intuition. Look at the sensitivity of the variables involved, and look at a wide swath of results before jumping to conclusions. And unless you have a clear reason to, don't arbitrarily assume probabilities. You probably don't know the difference between $0.1 \%$ and $1 \%$ without a good data set to aid you.
Optimal HORSE Strategy
Posted on July 14, 2019
Below is a solution to the Classic problem posed on July 12's edition of the Riddler on fivethirtyeight.com, "What’s The Optimal Way To Play HORSE?".
We will first introduce the game, then walk through a simulation, then the analytic solutions for the simplified game of $\mathrm{H}$ then the full game of $\mathrm{HORSE}$. We'll show that the optimal strategy regardless of the number of letters in the game is to always shoot the highest percentage shot (short of a 100% shot).
Intuitive Strategies
Two strategies immediately come mind. First, take a shot that maximizes the probability of you making a basket and him missing.
The second, and provably better strategy is to take advantage of the one thing you have (you are equally good shooters). You get to go first, so take full advantage of that turn, and maximize the probability of scoring a point before you miss.
Intuitive strategies are meaningless unless testing, so let's see what works best.
Simulation and Optimal Strategy
The code below is a bare bones implementation of a simulation. Player A and Player B can be assigned two different strategies, a_prob and b_prob, and the length of the game can be changed.
import random
def make_basket(prob):
if prob > random.random():
return True
else:
return False
def run_simulation(a_prob, b_prob, horse):
a_score = 0
b_score = 0
a_turn = True
while True:
if a_turn:
if make_basket(a_prob):
if make_basket(a_prob):
pass # both make
else:
a_score += 1 # a make, b miss
else:
a_turn = False # a misses, it's b's turn
else:
if make_basket(b_prob):
if make_basket(b_prob):
pass # both make
else:
b_score += 1 # b make, a miss
else:
a_turn = True # b misses, it's a's turn
if a_score >= horse or b_score >= horse:
break
return a_score, b_score
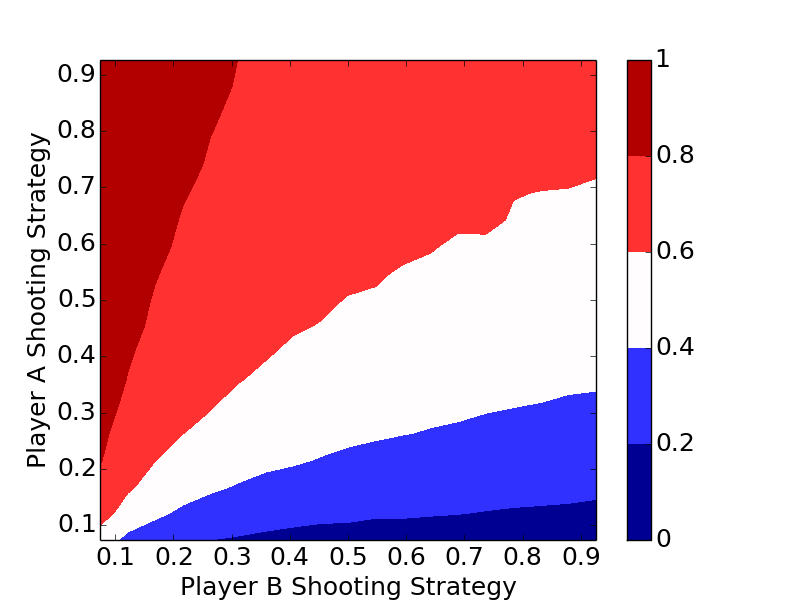
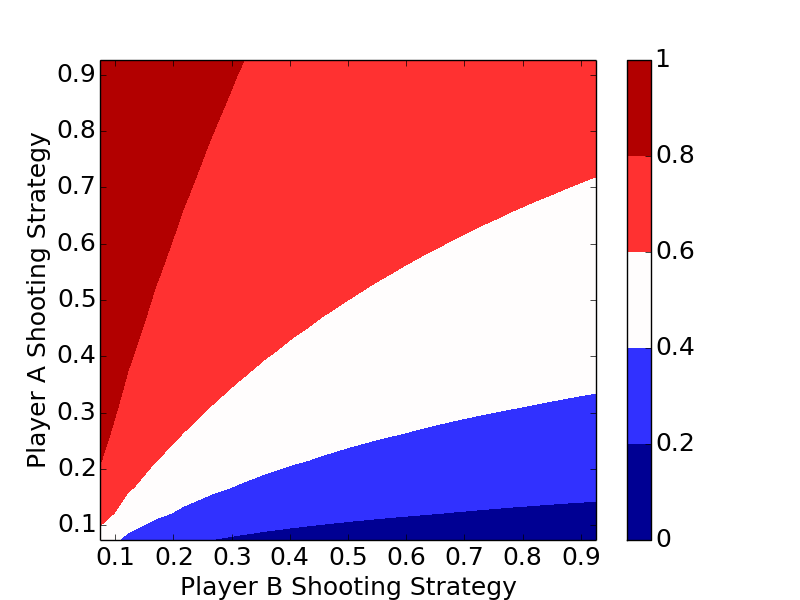
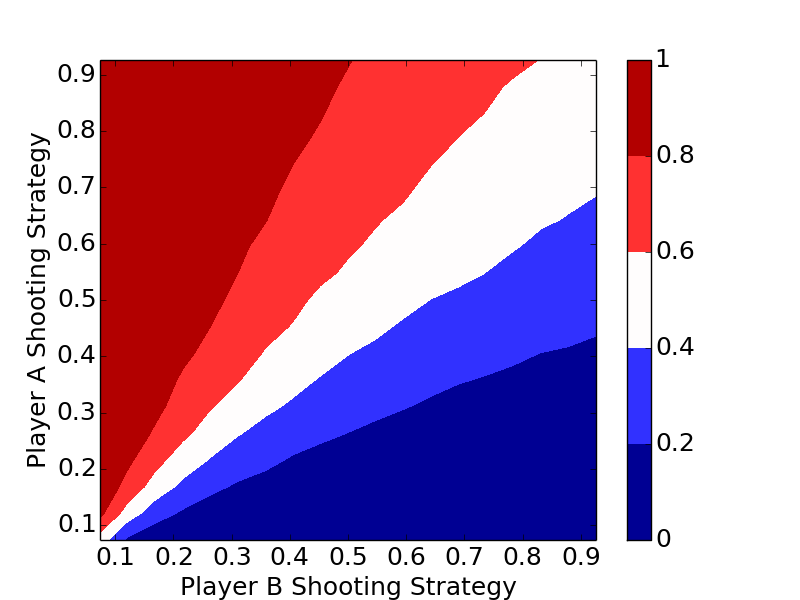
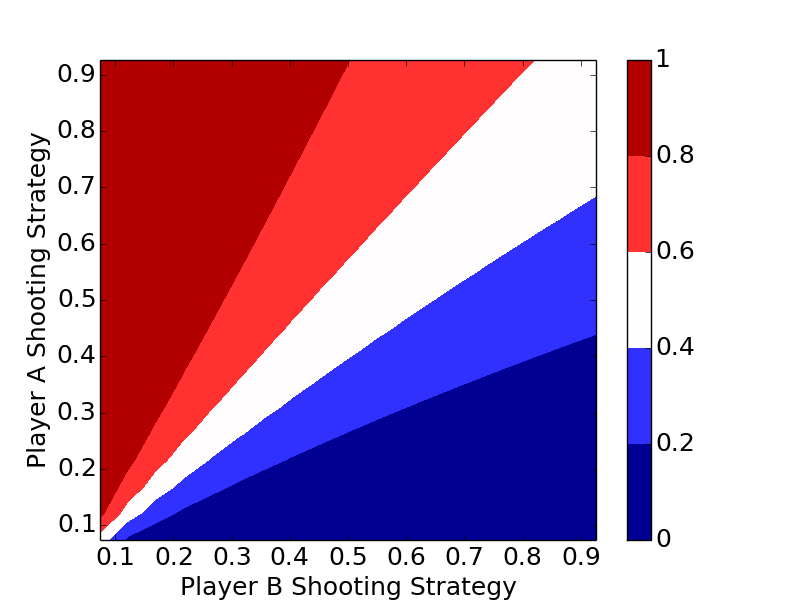
The plots clearly show the optimal strategy regardless of the number of letters in the game is to always shoot the highest percentage shot (short of a 100% shot).
Analytic Solution to $\mathrm{H}$
Let's consider the probability of Player A winning a point before losing their turn. Let $a$ be the probability of Player A making a basket. Then they could make a point in two shots with $p_2(a)=a(1-a)$, in four shots with $p_4(a)=a^3(1-a)$, or in general, in $2n$ shots with $p_{2n}(a)=a^{2n-1}(1-a)$. Therefore, the probability $p_A$ of winning a letter before losing their turn is $$p_A=\sum{p_i(a)}=a(1-a)+a^3(1-a)+... = \frac{a(1-a)}{1-a^2}=\frac{a}{a+1}.$$
The maximum value of this function on $[0,1]$ occurs at $a=1$, with $p_A(a)=0.5$. We wouldn't want to shoot a basket neither player ever misses, a trivial solution and never ending game, but we want to pick the shot closest to that.
We'll expand from winning a point without losing a turn, to winning the game of $H$, another geometric sequence. Let the player's probabilities of winning a point without losing a turn be $p_A$ and $p_B$ respectively. Player A could win on the first turn with probability $p_{AH_{1}}=p_A$, on the third turn with probability $p_{AH_{3}}=(1-p_A)(1-p_B)p_A$, and in $2n+1$ turns with probability $$p_{AH_{ 2n+1}}=(1-p_A)^{n}(1-p_B)^np_A$$
Similarly, the probability that Player A wins $H$, $p_{AH}$, is this sum $$p_{AH}=\sum{p_{AH_{2n+1}}}= \frac{p_A}{1-r}.$$ Where $p_A=\displaystyle\frac{a}{a+1}$, $p_B=\displaystyle\frac{b}{b+1}$, and $r=(1-p_A)(1-p_B)$.
As a sanity check, one could sum the terms of the geometric series for the probability of Player B winning, $\displaystyle\frac{(1-p_A)p_B}{1-r}$, add it to the probability of A winning, and find their sum is one, as it should be.
Analytic Solution to $\mathrm{HORSE}$
Expanding to multi-letter games is no longer a game of compounded geometric series, but instead of counting combinations. You can start by thinking of winning $\mathrm{HORSE}$ the same way as winning a five-game series. Unfortunately, it gets a little more complicated; your probability of winning a letter is based off whether or not you won the previous letter.
Let $A$ denote a Player A point win, and $B$ denote a Player B point win. Consider the game $AAAAA$. On each round, Player A starts, so they have the advantage; their probability of winning each point is $P_{AH}$.
Now consider, $ABAAAA$. The Player A win on point 3 following the Player B win, has the lower likelihood $(1-P_{BH})$ of occurring since Player B had the advantage of starting with the ball after winning point 2.
What makes the counting challenging is that the sequences $AABBBAAA$ and $ABABABAA$, for example, do not have the same probabilities for Player A winning. The first only has two "switches" from who is in control (shooting first), where the second has six switches, changing the probabilities in different ways. There is no way around working through each of the individual $1+5+15+35+70=126$ cases for Player A winning in five through nine games respectively.
The code below summarizes this counting.
probs = [.05*i for i in range(1,20)]
for a in probs:
for b in probs:
pa = a / (1 + a)
pb = b / (1 + b)
r = (1 - pa) * (1 - pb)
pAH = pa / (1 - r) # probability a wins going first
pBH = pb / (1 - r) # probability b wins going first
pAB = (1 - pAH, pAH)
cum_p = 0 # cumulative probability
for s in ['1111', '01111', '001111', '0001111', '00001111']:
tups = list(perm_unique(s))
for tup in tups:
seq = [int(i) for i in list(tup)+['1']]
p = pAB[seq[0]]
for i in range(1, len(seq)):
if seq[i-1] == 0 and seq[i] == 0:
p *= pBH
elif seq[i-1] == 1 and seq[i] == 0:
p *= (1 - pAH)
elif seq[i-1] == 0 and seq[i] == 1:
p *= (1 - pBH)
elif seq[i-1] == 1 and seq[i] == 1:
p *= pAH
cum_p += p
print cum_p,
print ""
My code makes use of some StackOverflow code to make unique permutations.
Winning Lotería and Countdown
Posted on June 2, 2019
Updated on June 4, 2019
I made a few changes from the original post. I misread allowable order of operations (the equivalent of "parentheses are ok", which drastically increases solvable numbers). I decided to leave it in as an interesting twist on the problem.
I also left out the case of six small numbers (another misread), which I have since added.
Below are solutions to the Classic and Express problems posed on May 31's edition of the Riddler on fivethirtyeight.com, "Can You Win The Lotería?".
Riddler Express - Lotería
First, a brief solution to the Riddler Express. The question posed is: for $N=54$ total images, and $n=16$ images per player card, how often will the game end with one empty card of images?
Two things must be considered: how often do the two players have unique cards (a necessary condition), and if that is met, how often will an entire card be filled before any images on the second card are filled?
We must first consider the necessary condition that the players have unique images on their cards. It helps to think about image "selection" successively. The first player can pick their entire card without concern. Then the second player "picks" their images for the second card one by one. For $N=54$ and $n=16$, there are $54$ options, $54-16=38$ of which are favorable, so probability the first image for the second card is not on the first card is $\frac{38}{54}$. The second image cannot be the first (and will not be the previous image), so there are now $53$ options, $37$ of which are favorable, yielding a probability of $\frac{37}{53}$. Continuing this logic, the probability the cards are unique is
$$ \frac{38}{54}\cdot\frac{37}{53}\cdot\frac{36}{52}\cdot...\cdot\frac{23}{39} \approx 0.001054.$$In general, the probability can be written as
$$ \displaystyle\frac{\binom{N-n}{n}}{\binom{N}{n}}.$$ Second, assuming the two cards are unique, how often will you win before the other player crosses a single image off their card? The extraneous cards are meaningless, akin to burn cards. WLOG, if you have images $1$-$16$, your opponent has $17$-$32$, then the favorable outcomes are all $16!$ arrangements of your cards, followed by all $16!$ arrangements of your opponents outcomes. The total number of arrangements is $32!$, the arrangements of all cards. The probability is then $$ \displaystyle\frac{16!\cdot 16!}{32!} \approx 1.664\times 10^{-9}. $$In general, the probability can be written as
$$ \displaystyle\frac{(n!)^2}{(2n)!}. $$Note, there is no $N$ term in this expression. The simulation in the code below considers all $N$ cards to verify its invariance.
from ncr import ncr #n choose r
import numpy as np
def you_win(photo_order, n):
"""WLOG you have photos 0 to n-1, opponent has n to 2n-1
Check if all of your photos appear before any of your opponents"""
n_count = 0
for i in photo_order:
if i < n:
n_count += 1
if n <= i < 2*n:
return False
if n_count == n:
return True
def main():
N = 54 # Total number of photos
n = 16 # Number of photos per player
num_sim = 10000 # Number of simulations
# Simulate Unique
count = 0
for _ in xrange(num_sim):
list_1 = np.random.choice(N, n, replace=False) # Your photos
list_2 = np.random.choice(N, n, replace=False) # Opponent's photos
if set(list_1) & set(list_2): # Check for intersection
count += 1
print "probability unique:", \
ncr(N-n, n) / float(ncr(N, n)), \
1.0 - count / float(num_sim)
# Simulate You Win
count = 0
for _ in xrange(num_sim):
photo_order = np.arange(N)
np.random.shuffle(photo_order)
if you_win(photo_order, n):
count += 1
print "probability you win:", 1./ncr(2 * n, n), count / float(num_sim)
if __name__ == "__main__":
main()
Riddler Classic - Countdown
$\newcommand{\Lone}{\mathrm{L}_{1}}$ $\newcommand{\Ltwo}{\mathrm{L}_{2}}$ $\newcommand{\Lthree}{\mathrm{L}_{3}}$ $\newcommand{\Lfour}{\mathrm{L}_{4}}$ $\newcommand{\a}{\mathrm{a}}$ $\newcommand{\b}{\mathrm{b}}$ $\newcommand{\c}{\mathrm{c}}$ $\newcommand{\d}{\mathrm{d}}$ $\newcommand{\e}{\mathrm{e}}$The remainder of this post will focus on the countdown problem, namely a brute force approach to counting all possible outcomes in a reasonable amount of time, follwed by a discussion of results. See code here.
The most fruitful combination is shown to be $5$, $6$, $8$, $9$, $75$, $100$, which yields $691$ different three-digit numbers. The least fruitful is shown to be $1$, $1$, $2$, $2$, $3$, $25$, which yields only $20$ different three-digit numbers.
Statistics for the various strategies (selecting 1 through 4 large numbers) are summarized, and it is shown that selecting two large numbers is the most advantageous, followed closely by selecting three large numbers.
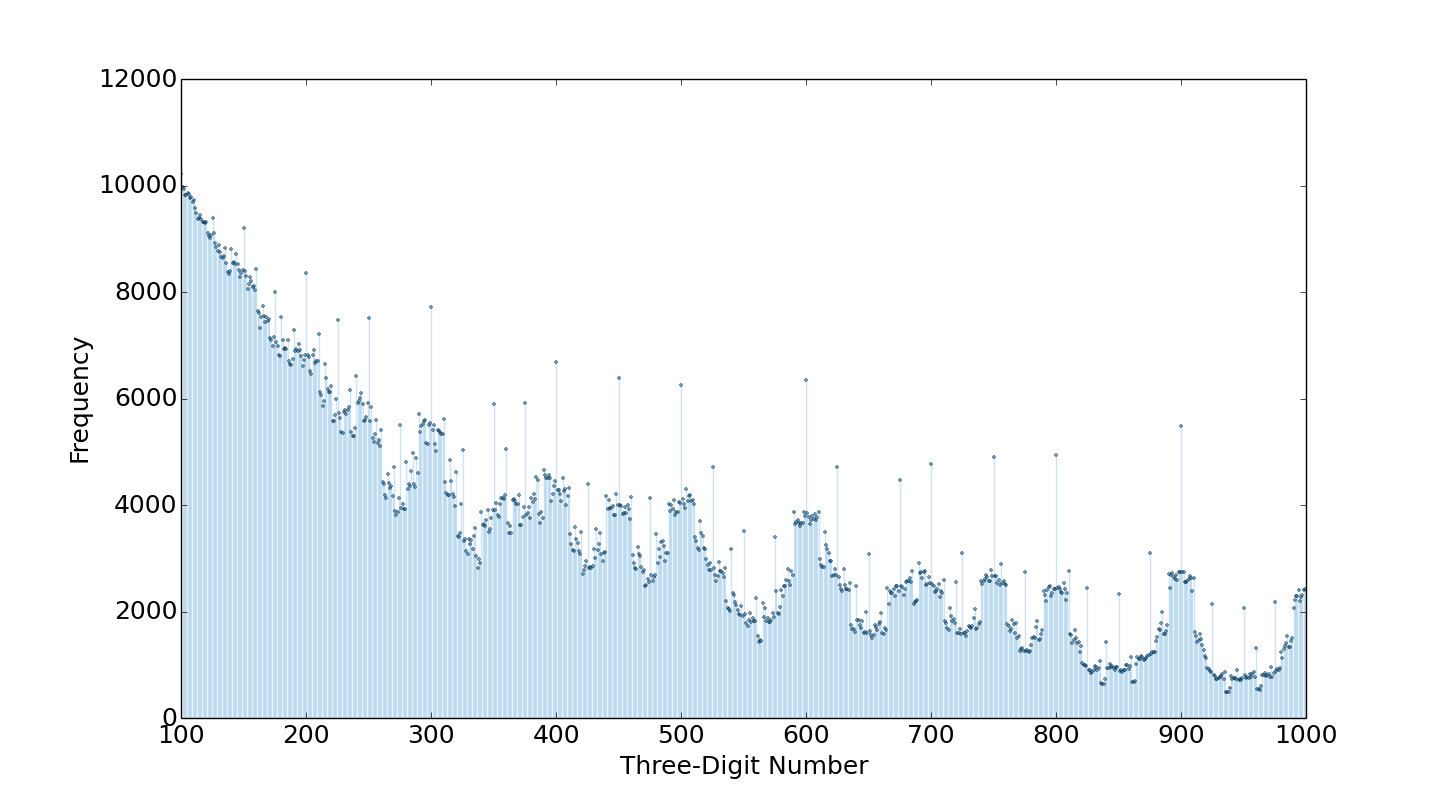
Finally, a histogram of the three-digit numbers frequency among the $10,603$ combinations shows what is intuitive, at least in hindsight: smaller three-digit numbers, and multiples of $25$, $50$, and especially $100$ are the most common.
Generating Combinations
First we must consider all possible combinations of the small and large numbers. We will denote large numbers with $\Lone$, $\Ltwo$, $\Lthree$, and $\Lfour$ and small numbers with $\a$, $\b$, $\c$, $\d$ and $\e$. A player can selected between zero and four large numbers, and the small numbers may repeat once. There are $11$ possible scenarios, divided by double lines in the table below by strategy.
| Pattern | Number of Combinations |
|---|---|
| $\a\b\c\d\e\mathrm{f}$ | $\binom{10}{6}$ |
| $\Lone\a\a\b\b\c$ | $\binom{4}{1}\cdot\binom{10}{2}\cdot\binom{8}{1}$ |
| $\Lone\a\a\b\c\d$ | $\binom{4}{1}\cdot\binom{10}{1}\cdot\binom{9}{3}$ |
| $\Lone\a\b\c\d\e$ | $\binom{4}{1}\cdot\binom{10}{5}$ |
| $\Lone\Ltwo\a\a\b\b$ | $\binom{4}{2}\cdot\binom{10}{2}$ |
| $\Lone\Ltwo\a\a\b\c$ | $\binom{4}{2}\cdot\binom{10}{2}\cdot\binom{8}{1}$ |
| $\Lone\Ltwo\a\b\c\d$ | $\binom{4}{2}\cdot\binom{10}{4}$ |
| $\Lone\Ltwo\Lthree\a\a\b$ | $\binom{4}{3}\cdot \binom{10}{1}\cdot \binom{9}{1}$ |
| $\Lone\Ltwo\Lthree\a\b\c$ | $\binom{4}{3}\cdot\binom{10}{3}$ |
| $\Lone\Ltwo\Lthree\Lfour\a\a$ | $\binom{4}{4}\cdot\binom{10}{1}$ |
| $\Lone\Ltwo\Lthree\Lfour\a\b$ | $\binom{4}{4}\cdot\binom{10}{2}$ |
Generating Permutations
These can be generated individually with the help of the Python itertools library. As a sample, consider $\Lone\Ltwo\a\a\b\c$.
import itertools
L_array = [25., 50., 75., 100.]
s_array = [float(i) for i in range(1, 11)]
for s in itertools.combinations(s_array, 3):
for L in itertools.combinations(L_array, 2):
for s0 in s:
loop_array = itertools.permutations(list(L) + list(s) + [s0])
This is probably the most complicated of the $11$ examples. Note the use of itertools.combinations vs itertools.permutations, the latter provides all arrangements and the former does not, which helps us reduce over counting. Over counting is not completely avoided however. The itertools library does not know that our two $\a$ values are repeats so we are over counting by a factor of $2$. This is not ideal, but the storage mechanism used (based on Python sets and dicts) eliminates error duplicate counting, so the only sacrifice is run time.
Considering Operators: $+-\times\div$
We will now take each permutation generated and loop through it's components left to right (i.e. consider the first number, then the first two numbers, then the first three, etc.). For example, given the permutation $100$, $50$, $10$, $2$, $7$, $4$, the first number "generated" is $100$. We then need to check all operations with the first two terms, $100+50$, $100-50$, $100\times 50$, and $100\div 50$ which yields $150$, another hit, but three numbers, $50$, $5000$, and $2$ that are not hits. Those last three numbers are not hits, but cannot be ignored since additional terms may turn them into hits; for example $100\times 50\div 10\div 2=250$ is another hit.
Challenges also arise with the implementation of addition, subtraction, multiplication and division operations in this left-to-right paradigm. We have $5$ spaces in between the $6$ numbers for each operation, for $4^5=1024$ possible permutations of the operators. However, we must only consider those where left to right operation satisfies order of operations. For example, $+$ $-$ $+$ $-$ $-$, $\div$ $\times$ $\div$ $\times$ $\div$, and $\times$ $\div$ $-$ $-$ $+$ are all acceptable but $+$ $\times$ $-$ $-$ $-$ because placing addition before multiplication is the equivalent of adding parentheses. Using the above example, $100+50+10\times2$
Acceptable orders of operation can be found with the following code. This finds all lists of five operators where all multiplication and division occur before all addition and subtraction.
operator_list = [] # Indices for operators, 0,1,2,3 is *,/,+,-
for i4 in xrange(4 ** 5):
cl = [i4 // 256 % 4, i4 // 64 % 4, i4 // 16 % 4, i4 // 4 % 4, i4 % 4]
if good_order(cl):
operator_list.append(cl)
print len(operator_list) # 192
Proving that this covers every possible case is not simple, but it makes intuitive sense that when all permutations of the 6 numbers are considered, the $192$ operators considered are exhaustive.
We now have everything we need to search for every combination. Full implementation can be found here.
A Brief Summary of Results
The combination $5$, $6$, $8$, $9$, $75$, $100$, yields $691$ different possible three-digit numbers, the most for any combination. The combination $1$, $1$, $2$, $2$, $3$, $25$, yields only $20$ possible combinations, the fewest. The top and bottom ten combinations are summarized in the tables below.
| Number | Number of three-digit numbers created |
|---|---|
| $5$, $6$, $8$, $9$, $75$, $100$ | $691$ |
| $5$, $7$, $8$, $9$, $75$, $100$ | $652$ |
| $6$, $7$, $9$, $10$, $75$, $100$ | $650$ |
| $6$, $8$, $9$, $10$, $75$, $100$ | $648$ |
| $3$, $8$, $9$, $10$, $75$, $100$ | $648$ |
| $2$, $5$, $6$, $9$, $75$, $100$ | $643$ |
| $5$, $6$, $8$, $9$, $50$, $100$ | $641$ |
| $5$, $6$, $7$, $9$, $75$, $100$ | $640$ |
| $2$, $5$, $8$, $9$, $75$, $100$ | $638$ |
| $4$, $7$, $9$, $10$, $75$, $100$ | $636$ |
| Number | Number of three-digit numbers created |
|---|---|
| $1$, $1$, $2$, $2$, $3$, $25$ | $20$ |
| $1$, $1$, $2$, $2$, $4$, $25$ | $21$ |
| $1$, $1$, $2$, $3$, $3$, $25$ | $25$ |
| $1$, $1$, $3$, $4$, $4$, $25$ | $34$ |
| $1$, $1$, $2$, $2$, $6$, $25$ | $35$ |
| $1$, $1$, $2$, $2$, $9$, $25$ | $35$ |
| $1$, $1$, $2$, $2$, $5$, $25$ | $35$ |
| $1$, $1$, $2$, $2$, $7$, $25$ | $35$ |
| $1$, $1$, $2$, $2$, $4$, $50$ | $36$ |
| $1$, $1$, $2$, $4$, $4$, $25$ | $36$ |
The table below shows that the best choice to pick two large numbers and four small numbers, but the strategy of picking three large is a close second. An outcome is defined as a three-digit number generated by a particular combination.
| Pattern | Arrangements | Total Outcomes | Average # of Outcomes |
|---|---|---|---|
| $\a\b\c\d\e\mathrm{f}$ | $210$ | $46,663$ | $222.2$ |
| $\Lone\a\a\b\b\c$ | $1440$ | $257,167$ | $178.6$ |
| $\Lone\a\a\b\c\d$ | $3360$ | $865,253$ | $257.5$ |
| $\Lone\a\b\c\d\e$ | $1008$ | $349,921$ | $347.1$ |
| One large | $253.5$ | ||
| $\Lone\Ltwo\a\a\b\b$ | $270$ | $58,221$ | $215.6$ |
| $\Lone\Ltwo\a\a\b\c$ | $2160$ | $694,966$ | $321.7$ |
| $\Lone\Ltwo\a\b\c\d$ | $1260$ | $574,520$ | $456.0$ |
| Two large | $\pmb{359.8}$ | ||
| $\Lone\Ltwo\Lthree\a\a\b$ | $360$ | $100,324$ | $278.7$ |
| $\Lone\Ltwo\Lthree\a\b\c$ | $480$ | $199,349$ | $415.3$ |
| Three large | $356.8$ | ||
| $\Lone\Ltwo\Lthree\Lfour\a\a$ | $10$ | $1,541$ | $154.1$ |
| $\Lone\Ltwo\Lthree\Lfour\a\b$ | $45$ | $10,619$ | $236.0$ |
| Four large | $221.1$ |
The histogram shows what we would intuitively expect, smaller numbers can be computed more often. There are also peaks at multiples of $25$, $50$, and especially $100$, another intuitive byproduct.
Flipping Astronauts
Posted on May 26, 2019
Introduction
This is a solution to the problem posed on May 24's edition of the Riddler Classic on fivethirtyeight.com, "One Small Step For Man, One Giant Coin Flip For Mankind".
We will show that there are $12$ non-trivial solutions to the $3$-astronaut problem with $4$ coins and $2$ non-trivial solutions to the $5$-astronaut problem with $6$ coins.
Three Astronauts
The problem statement walks through the impossibility of using two coins, with $2^2=4$ outcomes, to determine a winner for three astronauts. The same can be said for three flips, which we will briefly discuss.
The key to attacking this problem for an $n$-astronaut scenario is equally distributing outcomes amongst the first $n-1$ astronauts. For the $3$-astronaut, $3$-flip case this translates to the following: among the $1$, $3$, $3$, and $1$ outcomes ($0$ heads, $1$ head, $2$ heads, and $3$ heads respectively), the first and second astronauts should have the same number each of $0$-head, $1$-head, $2$-head, and $3$-head outcomes. One possible assignment that meets this parameter is for the first and second astronauts to each have the distributions $0$, $1$, $1$, $0$, leaving the third astronaut with the distribution $1$, $1$, $1$, $1$. This is summarized in the table, below.
| 3 Heads 0 Tails | 2 Heads 1 Tail | 1 Head 2 Tails | 0 Heads 3 Tails |
|
|---|---|---|---|---|
| Astro #1 | 0 | 1 | 1 | 0 |
| Astro #2 | 0 | 1 | 1 | 0 |
| Astro #3 | 1 | 1 | 1 | 1 |
| Total | 1 | 3 | 3 | 1 |
This distribution, however, implies that the probability of flipping three heads and zero heads is both zero, a contradiction. All distributions with $3$ astronauts and $3$ coins yield similar contradictions.
There is no rigorous proof here to the claim that the first $n-1$ astronauts must have the same distribution of outcomes, but the likelihood of them having different outcomes that independently add up to a very specific fraction is highly unlikely. Further work below will show it's analogous to polynomials with different integer coefficients having an identical real root between $0$ and $1$.
We broaden our horizons to a $4$-coin solution, which has the $2^4=16$ outcomes of $1$, $4$, $6$, $4$, $1$, for $4$, $3$, $2$, $1$, and $0$ heads respectively. For three astronauts, we have significantly more ways to distribute the coin flips. For example, the first two astronauts could each be given the outcome distribution $0$, $2$, $3$, $2$, $0$, leaving $1$, $0$, $0$, $0$, $1$ for the third astronaut. This is summarized in the table, below.
| 4 Heads 0 Tails | 3 Heads 1 Tail | 2 Heads 2 Tails | 1 Head 3 Tails | 0 Heads 4 Tails |
|
|---|---|---|---|---|---|
| Astro #1 | 0 | 2 | 3 | 2 | 0 |
| Astro #2 | 0 | 2 | 3 | 2 | 0 |
| Astro #3 | 1 | 0 | 0 | 0 | 1 |
| Total | 1 | 4 | 6 | 4 | 1 |
We now have to see if a solution exists with this distribution. Let $h$ be the probability of flipping a heads, and $t=1-h$ be the probability of flipping a tails. We generate the probabilities of each flipping outcome: for $k$ heads in $n$ flips, a specific outcome (ignoring rearrangments) is $h^k t^{n-k} = h^k (1-h)^{n-k}$. Using the current example from the above table, our probability polynomial for astronaut 1 (and equivalently astronaut 2) becomes
\begin{eqnarray} 2 h^3 (1-h) + 3 h^2 (1-h)^2 + 2 h (1-h)^3 &=& \frac{1}{3} \\ -h^4 + 2h^3 -3 h^2 + 2h &=& \frac{1}{3} \end{eqnarray} $$ h = \frac{1}{6} \left( 3 \pm \sqrt{3 \left(4\sqrt{6} -9\right)} \right) \approx 0.242, 0.758 $$Therefore, we can state that one solution is with $h=.242$, the first astronaut getting assigned $2$, $3$, and $2$ each of the $3$-head, $2$-head, and $1$-head outcomes, and the third astronaut being assigned the $4$-head and $0$-head outcomes.
As an aside, it makes sense to have symmetric solutions here (that is, they add up to $1$), since we picked symmetric coefficients $2$, $3$, and $2$. We expect an asymmetric pick like $1$, $3$, $2$ to not yield symmetric solutions.
Let's generalize further to find all $3$-astronaut, $4$-coin solutions. There are $4$ outcomes with $3$ heads, so astronauts one and two could each get $0$, $1$, or $2$. Similarly they could get $0$, $1$, $2$, or $3$ and $0$, $1$, or $2$ of the $2$-head outcomes and $1$-head outcomes respectively. We need to test all of these scenarios, which we accomplish using the following code.
import numpy as np
import operator as op
from functools import reduce
from collections import namedtuple
Solution = namedtuple('Solution', 'coefficients roots')
def ncr(n, r):
"""Implementation of n choose r = n!/(r!*(n-r)!)"""
r = min(r, n-r)
numer = reduce(op.mul, range(n, n-r, -1), 1)
denom = reduce(op.mul, range(1, r+1), 1)
return numer / denom
def create_polys(num_coins):
"""Creates polynomial expansions in list form for n-1 to 1 heads"""
polys = []
for i in range(1, num_coins):
poly = []
neg = (-1)**i
for j in range(0, i+1):
poly.append(ncr(i, j) * neg)
neg *= -1
for k in range(i+1, num_coins):
poly.append(0)
polys.append(poly)
return polys
def create_coeff_limits(num_coins, num_astronauts):
"""Determines the maximum allocation of head/tail outcomes based off the number of coins and astronauts"""
coeffs = []
for i in range(1, num_coins):
coeffs.append(ncr(num_coins, i) // (num_astronauts - 1) + 1)
return coeffs
def is_valid_solution(root):
"""Checks if root is valid. Must be real and between 0 and 1."""
return np.isreal(root) and 0 < root < 1
def solve_poly(coeffs, polys, prob):
"""Generates and solves polynomials using np.roots
coeffs: list of "coefficients", i.e. multipliers for the number of out head/tail outcomes
polys: generated with create_polys
prob: the negated probability -1/num_astronauts
returns all valid solutions a list on named tuples
"""
sum_poly = []
valid_solutions = []
for degree in range(len(polys[0])):
term = 0
for j in range(len(polys)): # for each polynomial
term += coeffs[j] * polys[j][degree]
sum_poly.append(term)
sum_poly.append(prob)
ans = np.roots(sum_poly)
for root in ans:
if is_valid_solution(root):
valid_solutions.append(Solution(coeffs, root))
return valid_solutions
def main():
num_astronauts = 3
num_coins = 6
prob = -1.0/num_astronauts
polys = create_polys(num_coins)
coeff_limits = create_coeff_limits(num_coins, num_astronauts)
solutions = []
# Loop through all possible coefficient combinations
coeff_dividers = []
for i in range(1, len(coeff_limits)):
coeff_dividers.append(reduce(op.mul, coeff_limits[i:], 1))
# This helps us avoid recursion and nested for loops
for i in range(reduce(op.mul, coeff_limits, 1)):
coeffs = []
for j in range(len(coeff_dividers)):
coeffs.append((i // coeff_dividers[j]) % coeff_limits[j])
coeffs.append(i % coeff_limits[-1])
solutions += solve_poly(coeffs, polys, prob)
for solution in solutions:
print solution.coefficients, np.real(solution.roots) #strip 0.j
print "Number of solutions:", len(solutions)
if __name__ == '__main__':
main()
This code, with num_astronauts=3 and num_coins=4 yields the following 12 solutions, where the five listed values correspond to distributions with $4$, $3$, $2$, $1$, and $0$ heads respectively.
| $h$ | Astronauts 1 & 2 | Astronaut 3 |
|---|---|---|
| 0.4505 | 0, 0, 3, 2, 0 | 1, 4, 0, 0, 1 |
| 0.2861 | 0, 0, 3, 2, 0 | 1, 4, 0, 0, 1 |
| 0.6051 | 0, 1, 3, 2, 0 | 1, 2, 0, 0, 1 |
| 0.2578 | 0, 1, 3, 2, 0 | 1, 2, 0, 0, 1 |
| 0.6967 | 0, 2, 2, 2, 0 | 1, 0, 2, 0, 1 |
| 0.3033 | 0, 2, 2, 2, 0 | 1, 0, 2, 0, 1 |
| 0.7139 | 0, 2, 3, 0, 0 | 1, 0, 0, 4, 1 |
| 0.5495 | 0, 2, 3, 0, 0 | 1, 0, 0, 4, 1 |
| 0.7422 | 0, 2, 3, 1, 0 | 1, 0, 0, 2, 1 |
| 0.3949 | 0, 2, 3, 1, 0 | 1, 0, 0, 2, 1 |
| 0.7579 | 0, 2, 3, 2, 0 | 1, 0, 0, 0, 1 |
| 0.2421 | 0, 2, 3, 2, 0 | 1, 0, 0, 0, 1 |
Five Astronauts
The problem is easily generalized with the above code to higher numbers of astronauts. There are two solutions for $5$ astronauts and $6$ coins, where the seven listed values correspond to distributions with $6$, $5$, $4$, $3$, $2$, $1$, and $0$ heads respectively.
| $h$ | Astronauts 1, 2, 3, & 4 | Astronaut 5 |
|---|---|---|
| 0.4326 | 0, 1, 3, 5, 3, 1, 0 | 1, 2, 3, 0, 3, 2, 1 |
| 0.5674 | 0, 1, 3, 5, 3, 1, 0 | 1, 2, 3, 0, 3, 2, 1 |
We can also search for solutions with larger numbers of coins. The $64$ solutions for $5$ astronauts and $7$ coins are listed in the table below, where the eight listed values correspond to distributions with $7$, $6$, $5$, $4$, $3$, $2$, $1$, and $0$ heads respectively.
| $h$ | Astronauts 1, 2, 3, & 4 | Astronaut 5 |
|---|---|---|
| 0.4662 | 0, 0, 3, 8, 8, 5, 1, 0 | 1, 7, 9, 3, 3, 1, 3, 1 |
| 0.3636 | 0, 0, 3, 8, 8, 5, 1, 0 | 1, 7, 9, 3, 3, 1, 3, 1 |
| 0.4536 | 0, 0, 4, 7, 8, 5, 1, 0 | 1, 7, 5, 7, 3, 1, 3, 1 |
| 0.3863 | 0, 0, 4, 7, 8, 5, 1, 0 | 1, 7, 5, 7, 3, 1, 3, 1 |
| 0.5215 | 0, 0, 4, 8, 8, 5, 1, 0 | 1, 7, 5, 3, 3, 1, 3, 1 |
| 0.3468 | 0, 0, 4, 8, 8, 5, 1, 0 | 1, 7, 5, 3, 3, 1, 3, 1 |
| 0.527 | 0, 0, 5, 7, 8, 5, 1, 0 | 1, 7, 1, 7, 3, 1, 3, 1 |
| 0.359 | 0, 0, 5, 7, 8, 5, 1, 0 | 1, 7, 1, 7, 3, 1, 3, 1 |
| 0.5343 | 0, 0, 5, 8, 7, 5, 1, 0 | 1, 7, 1, 3, 7, 1, 3, 1 |
| 0.3845 | 0, 0, 5, 8, 7, 5, 1, 0 | 1, 7, 1, 3, 7, 1, 3, 1 |
| 0.543 | 0, 0, 5, 8, 8, 4, 1, 0 | 1, 7, 1, 3, 3, 5, 3, 1 |
| 0.4207 | 0, 0, 5, 8, 8, 4, 1, 0 | 1, 7, 1, 3, 3, 5, 3, 1 |
| 0.5513 | 0, 0, 5, 8, 8, 5, 0, 0 | 1, 7, 1, 3, 3, 1, 7, 1 |
| 0.4487 | 0, 0, 5, 8, 8, 5, 0, 0 | 1, 7, 1, 3, 3, 1, 7, 1 |
| 0.5742 | 0, 0, 5, 8, 8, 5, 1, 0 | 1, 7, 1, 3, 3, 1, 3, 1 |
| 0.3363 | 0, 0, 5, 8, 8, 5, 1, 0 | 1, 7, 1, 3, 3, 1, 3, 1 |
| 0.4564 | 0, 1, 2, 8, 8, 5, 1, 0 | 1, 3, 13, 3, 3, 1, 3, 1 |
| 0.3758 | 0, 1, 2, 8, 8, 5, 1, 0 | 1, 3, 13, 3, 3, 1, 3, 1 |
| 0.5278 | 0, 1, 3, 8, 8, 5, 1, 0 | 1, 3, 9, 3, 3, 1, 3, 1 |
| 0.3532 | 0, 1, 3, 8, 8, 5, 1, 0 | 1, 3, 9, 3, 3, 1, 3, 1 |
| 0.5376 | 0, 1, 4, 7, 8, 5, 1, 0 | 1, 3, 5, 7, 3, 1, 3, 1 |
| 0.3673 | 0, 1, 4, 7, 8, 5, 1, 0 | 1, 3, 5, 7, 3, 1, 3, 1 |
| 0.5519 | 0, 1, 4, 8, 7, 5, 1, 0 | 1, 3, 5, 3, 7, 1, 3, 1 |
| 0.396 | 0, 1, 4, 8, 7, 5, 1, 0 | 1, 3, 5, 3, 7, 1, 3, 1 |
| 0.5674 | 0, 1, 4, 8, 8, 4, 1, 0 | 1, 3, 5, 3, 3, 5, 3, 1 |
| 0.4326 | 0, 1, 4, 8, 8, 4, 1, 0 | 1, 3, 5, 3, 3, 5, 3, 1 |
| 0.5793 | 0, 1, 4, 8, 8, 5, 0, 0 | 1, 3, 5, 3, 3, 1, 7, 1 |
| 0.457 | 0, 1, 4, 8, 8, 5, 0, 0 | 1, 3, 5, 3, 3, 1, 7, 1 |
| 0.5995 | 0, 1, 4, 8, 8, 5, 1, 0 | 1, 3, 5, 3, 3, 1, 3, 1 |
| 0.3409 | 0, 1, 4, 8, 8, 5, 1, 0 | 1, 3, 5, 3, 3, 1, 3, 1 |
| 0.5566 | 0, 1, 5, 6, 8, 5, 1, 0 | 1, 3, 1, 11, 3, 1, 3, 1 |
| 0.3849 | 0, 1, 5, 6, 8, 5, 1, 0 | 1, 3, 1, 11, 3, 1, 3, 1 |
| 0.5831 | 0, 1, 5, 7, 7, 5, 1, 0 | 1, 3, 1, 7, 7, 1, 3, 1 |
| 0.4169 | 0, 1, 5, 7, 7, 5, 1, 0 | 1, 3, 1, 7, 7, 1, 3, 1 |
| 0.604 | 0, 1, 5, 7, 8, 4, 1, 0 | 1, 3, 1, 7, 3, 5, 3, 1 |
| 0.4481 | 0, 1, 5, 7, 8, 4, 1, 0 | 1, 3, 1, 7, 3, 5, 3, 1 |
| 0.6155 | 0, 1, 5, 7, 8, 5, 0, 0 | 1, 3, 1, 7, 3, 1, 7, 1 |
| 0.4657 | 0, 1, 5, 7, 8, 5, 0, 0 | 1, 3, 1, 7, 3, 1, 7, 1 |
| 0.6287 | 0, 1, 5, 7, 8, 5, 1, 0 | 1, 3, 1, 7, 3, 1, 3, 1 |
| 0.351 | 0, 1, 5, 7, 8, 5, 1, 0 | 1, 3, 1, 7, 3, 1, 3, 1 |
| 0.6151 | 0, 1, 5, 8, 6, 5, 1, 0 | 1, 3, 1, 3, 11, 1, 3, 1 |
| 0.4434 | 0, 1, 5, 8, 6, 5, 1, 0 | 1, 3, 1, 3, 11, 1, 3, 1 |
| 0.6137 | 0, 1, 5, 8, 7, 4, 0, 0 | 1, 3, 1, 3, 7, 5, 7, 1 |
| 0.5464 | 0, 1, 5, 8, 7, 4, 0, 0 | 1, 3, 1, 3, 7, 5, 7, 1 |
| 0.6327 | 0, 1, 5, 8, 7, 4, 1, 0 | 1, 3, 1, 3, 7, 5, 3, 1 |
| 0.4624 | 0, 1, 5, 8, 7, 4, 1, 0 | 1, 3, 1, 3, 7, 5, 3, 1 |
| 0.641 | 0, 1, 5, 8, 7, 5, 0, 0 | 1, 3, 1, 3, 7, 1, 7, 1 |
| 0.473 | 0, 1, 5, 8, 7, 5, 0, 0 | 1, 3, 1, 3, 7, 1, 7, 1 |
| 0.649 | 0, 1, 5, 8, 7, 5, 1, 0 | 1, 3, 1, 3, 7, 1, 3, 1 |
| 0.3713 | 0, 1, 5, 8, 7, 5, 1, 0 | 1, 3, 1, 3, 7, 1, 3, 1 |
| 0.6242 | 0, 1, 5, 8, 8, 2, 1, 0 | 1, 3, 1, 3, 3, 13, 3, 1 |
| 0.5436 | 0, 1, 5, 8, 8, 2, 1, 0 | 1, 3, 1, 3, 3, 13, 3, 1 |
| 0.6364 | 0, 1, 5, 8, 8, 3, 0, 0 | 1, 3, 1, 3, 3, 9, 7, 1 |
| 0.5338 | 0, 1, 5, 8, 8, 3, 0, 0 | 1, 3, 1, 3, 3, 9, 7, 1 |
| 0.6468 | 0, 1, 5, 8, 8, 3, 1, 0 | 1, 3, 1, 3, 3, 9, 3, 1 |
| 0.4722 | 0, 1, 5, 8, 8, 3, 1, 0 | 1, 3, 1, 3, 3, 9, 3, 1 |
| 0.6532 | 0, 1, 5, 8, 8, 4, 0, 0 | 1, 3, 1, 3, 3, 5, 7, 1 |
| 0.4785 | 0, 1, 5, 8, 8, 4, 0, 0 | 1, 3, 1, 3, 3, 5, 7, 1 |
| 0.6591 | 0, 1, 5, 8, 8, 4, 1, 0 | 1, 3, 1, 3, 3, 5, 3, 1 |
| 0.4005 | 0, 1, 5, 8, 8, 4, 1, 0 | 1, 3, 1, 3, 3, 5, 3, 1 |
| 0.6637 | 0, 1, 5, 8, 8, 5, 0, 0 | 1, 3, 1, 3, 3, 1, 7, 1 |
| 0.4258 | 0, 1, 5, 8, 8, 5, 0, 0 | 1, 3, 1, 3, 3, 1, 7, 1 |
| 0.6678 | 0, 1, 5, 8, 8, 5, 1, 0 | 1, 3, 1, 3, 3, 1, 3, 1 |
| 0.3322 | 0, 1, 5, 8, 8, 5, 1, 0 | 1, 3, 1, 3, 3, 1, 3, 1 |
Bonus: Riddler Express
The code below is an brute-force solution to the Riddler Express problem about soccer team selection. The smallest solution found was with jersey numbers $1$, $5$, $6$, $8$, $9$, $10$, $12$, $15$, $18$, $20$, and $24$.
import itertools
def brute_soccer(team_list):
average_score = sum([1./i for i in team_list])
if abs(average_score-2.0) < 1e-8:
print team_list, average_score
for i in itertools.combinations(range(1, 25), 11):
brute_soccer(i)